
분산 학습에 대하여
단일 GPU또는 CPU를 이용하여 학습하는 경우 데이터 양과 학습 횟수에 따라 학습시간이 오래 걸리게 되는데, 이 시간을 단축시키기 위해서 여러 GPU또는 CPU에 분산하여 학습을 진행할 수 있다.
분산학습을 위한 프레임워크는 Tensorflow, Keras, Caffe2, MxNet, Horovod 등이 존재하는데, 본 포스팅에서는 Horovod라는 프레임워크에 대해 알아보겠다.
Horovod란?
Tensorflow, Keras, Pytorch, MXNet에서의 Multi-GPU를 활용한 Distributed Training을 지원하는 Framework이다. Horovod를 활용하면 적은 양의 코드를 추가하여 손쉽게 Distributed Training을 구현할 수 있다.
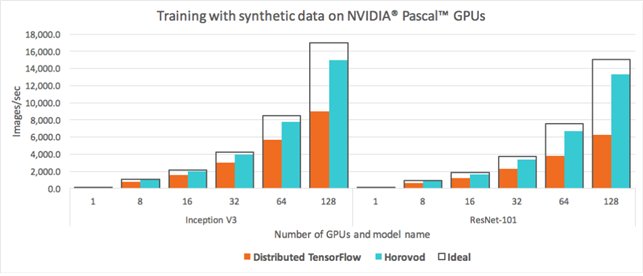
위 사진을 보시면 Tensorflow로 구현한 코드보다 Horovod를 이용한 코드의 학습량이 높은 것을 확인할 수 있다.
Horovod의 핵심 개념
MPI의 기본 개념으로 size, rank, local rank, Allreduce, Algather 그리고 Broadcast이다.
- size : 총프로세스의 수
- rank : 프로세스의 순위 (프로세스의 id)
- local rank : 서버 내의 프로세스 순위
- Allreduce : 하나의 Worker를 마스터로 놓고 다른 모든 Worker의 Data을 마스터로 모은 다음 마스터에서 각 Worker의 Data들을 동기화, 축소 작업(sum)을 하여 다시 다른 Worker들에게 배포하는 작업이다. (기본은 Allreduce이며 빠르고 확장 가능한 알고리즘으로 Ring-Allreduce가 있다. 단점으로는 모든 프로세스의 작업이 종료되어야지 가능하며 마스터 프로세스로 이동하기 때문에 병목현상이 발생할 수 있다.)
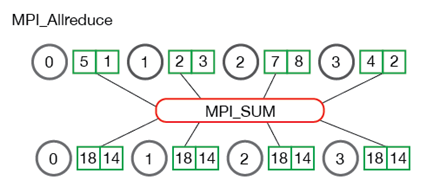
- Allgather : 각 Worker는 size만큼 청크를 만들고 해당 청크들을 전체 Worker에 전달하여 각 Worker내부에서 청크를 통하여 동기화 작업을 진행한다.

- Broadcast : 마스터 Worker에서 다른 Worker들에게 작업을 배포한다.

Tensorflow vs Horovod
1. 프로세스 설정
- Tensorflow의 경우 사용할 프로세스의 정보를 json객체 형태로 만들어 설정하거나 함수 호출
( tf.distribute.MirroredStrategy() ,
{
'cluster':{
'worker':["localhost:12345","localhost:23456"]
},
'task':{'type':'worker','index':0}
}
)- Horovod의 경우 총 몇 개의 프로세스를 사용할지 각 서버에서 몇 개를 사용할지 만 설정
horovodrun –np 8 –H server1:4,server2:42. 수정해야 할 소스코드의 양
- Tensorflow의 경우 프로세스 설정 객체 조회 코드, Worker별로 학습할 데이터분할 코드 등 추가 해야할 코드의 양이 많다.
- Horovod의 경우 내부적으로 함수로 설정되어 있어 추가 할 코드양은 적다.
3. 통신 속도
- Tensorflow2에서 NVIDIA의 NCCL라이브러리를 사용 할 수 있으므로 큰 차이는 나타나지 않는다.
마지막으로 Tensorflow2보다 Horovod가 프로세스 설정, 적은양의 코드로 분산학습(Distributed Training)을 쉽게 사용가능하므로 Muti-Node, Muti-GPU의 경우에는 Horovod를 사용하는 것이 좋다고 생각 하지만 각각의 장점 및 단점이 나타날 수 있으므로 판단은 각자의 몫이다.
Horovod 동작 방식
Horovod는 총 몇 개의 프로세스(또는 GPU)를 사용 할 것인지 정한 후 각 서버에서는 몇 개의 프로세스(GPU)를 사용하겠다고 설정하고 학습을 시작한다.(총 프로세스의 수와 서버들의 프로세스 합이 같아야 한다.)
학습 시작 시에는 마스터 프로세스를 정하고 마스터 프로세스에서 각 프로세스에 정보들을 Broadcast한며, 배포시에는 최대한 비슷한 학습을 할 수 있도록 Data와 학습 횟수를 총 프로세스의 수만큼 분할하여 배포하게 된다.
각 프로세스에서 학습을 진행하며 각 프로세스마다 다른 Gradient가 계산되고 각 프로세스의 Gradient를 동기화, 평균을 구하는 작업을 진행한다. 여기서 작업의 객체를 Array(배열)인지 Dictionary(key, value)인지에 따라 동기화 알고리즘이 달라진다.
- Array의 경우 해당 작업은 Allreduce 알고리즘을 이용하여 각 프로세스의 Gradient를 동기화
- Dictionary의 경우 해당 작업은 Allgather 알고리즘을 이용하여 각 프로세스의 Gradient를 동기화

추가 설명
- Horovod의 각 프로세스간의 통신은 MPI(message passing interface)방식으로 통신을 진행하게 되는데 해당 통신을 하기위해서는 MPI라이브러리를 설치해야 하는데 Horovod는 OpenMPI, Spectrum MPI, MPICH, Gloo NVIDIA의 NCCL라이브러리를 지원 한다.
- NCCL이란 NVIDIA에서 제작한 Muti-GPU 집단 통신 기본 라이브러리이다. AllReduce, Broadcast, Reduce, AllGather, ReduceScatter를 지원하며 통신 및 계산 작업을 모두 처리하는 단일 커널에서 각 집합을 구현을 통해 빠른 동기화가 가능하며 피크 대역폭에 도달하는 데 필요한 리소스가 최소화되며, 또한 노드 내 및 노드간에 여러 GPU에 대해 빠른 집합을 제공한다.
- Ring-AllReduce란 각 프로세스는 size만큼 청크를 만들고 첫 번째 프로세스는 두 번째 프로세스로 첫 번째 청크를 보내고 두 번째 프로세스는 세 번째 프로세스로 두 번째 청크를 보내는 방식으로 각 프로세스가 size만큼의 청크를 갖게되면 해당 알고리즘이 종료된다.

참고 자료
https://horovod.readthedocs.io/en/latest/concepts_include.html
https://www.tensorflow.org/tutorials/distribute/multi_worker_with_keras?hl=en
'인공지능 > 머신러닝, 딥러닝' 카테고리의 다른 글
| scikit-learn datasets 활용 (0) | 2020.07.03 |
|---|
인공지능/머신러닝, 딥러닝 카테고리의 다른 글
scikit-learn datasets 활용
2020.07.03